What is Kafka?
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. (Wikipedia).
Apache Kafka is a publish-subscribe based durable messaging system. A messaging system sends messages between processes, applications, and servers.
Topics:
A Topic is a category/feed name to which records are stored and published. A topic is a particular stream of data. Similar to a table name in a database.
Partitions:
Kafka topics are divided into a number of partitions, which contain records in an unchangeable sequence. Each record in a partition is assigned and identified by its unique offset. A topic can also have multiple partition logs. This allows multiple consumers to read from a topic in parallel. Each message in partition gets an incremental id called offset.
Offset:
- Offset are like indexes in an array.
- Order is guaranteed only within a partition (not across partitions)
- Data is kept only for a limited time (Default is one week)
- Data is assigned randomly to a partition unless a key is provided
Broker & Cluster:
Cluster is a collection of brokers. Brokers are the Kafka servers. Every Kafka broker is also called a “bootstrap server”. It means you only need to connect to one broker and you will be connected to the entire cluster.
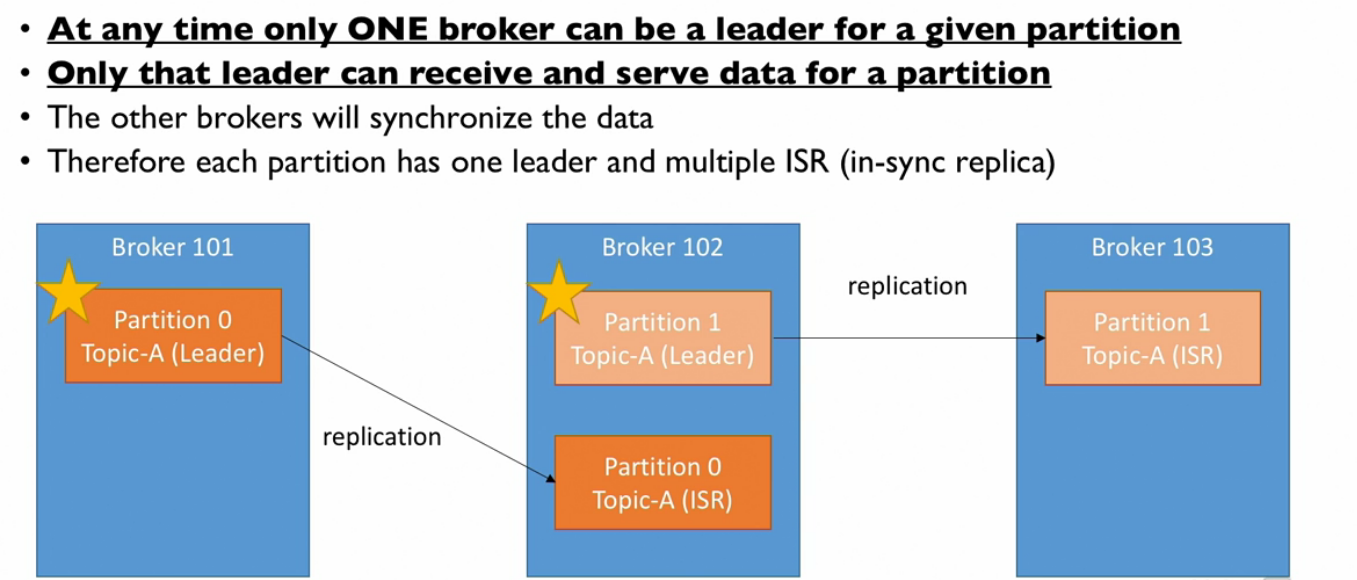
Leader:
- At any time one broker can be a leader for a given partition
- Only that leader can receive and serve data for a partition
- The other brokers will synchronize the data
- Therefore each partition has one leader and multiple ISR ( in-sync replica)
Replicas:
Replicas are nothing but backups of a partition. If the replication factor of a topic is set to 4, then Kafka will create four identical replicas of each partition and place them in the cluster to make them available for all its operations. Replicas are never used to read or write data. They are used to prevent data loss.
Producers:
Producers writes data to topics
Message Key:
Producers can choose to send a key with the message
- key=null: data is sent round robin (Broker0 then Broker1 then Broker2)
- key!=null: all messages for that key will always go to the same partition.
A key is sent if you need message ordering for a specific field.
Key Hashing:
- By default it uses "murmurmur2" algorithm
- Formula: targetPartion = Utils.abs(Utils.murmur2(recover.key())) % numPartitions
adding/removing partitions to a topic will completely alter the formula
Acknowledgement:
Producers can choose to receive acknowledgment of data writes
- ack = 0: Producers won't wait for acknowledgment ( Possible data loss)
- ack = 1: Producers will wait for leader acknowledgment ( limited data loss)
- Leader response is requested but replication is not a guarantee.
- If ack is not received, the producer may retry
- If leader broker goes offline but replicas haven't replicated the data yet, we have a loss of data
- ack = all: Leaders + replicas acknowledgment ( no data loss)
- Acks=all must be used in conjunction with min.insync.replicas
- min.insync.replicas can be set a the broker or topic level (Override)
- min.insync.replicas=2 implies that at least 2 brokers that are ISR(including leader) must response that they have data
- That means if you use replication.factor = 3, min.insync=2, ack=all, you can only tolerate I broker going down, otherwise the producer will receive an exception on send.
enable.idempotence=true ( producer level ) + min.insync.replicas=2 ( brokder/topic level)
implies ack=all, retries=MAX_INT, max.in.flight.requests.per.connection=5 (default)
Compression:
- Producer usually send data that is text-based e.g. with JSON data which are large in size
- In this case, it is important to apply compression to the producer
- Compression is enabled at the producer level doesn't require change at broker or in the consumer
Compression Type:
- "compression.type" can be 'none' (default), 'gzip', 'Iz4', 'snappy'
- compression is more effective on the bigger batch of data
- Always use compression if you have high throughput
- consider tweaking linger.ms and batch.size to have bigger batches and therefore more compression and higher throughput.
- By default, kafka tries to send records as soon as possible
- It will have up to 5 request in flight, meaning up to 5 messages individually sent at the same time
- After this if more message have to be sent while others are in flight, kafka is smart and will start batching them while they wait to send them all at once.
Linger.ms:
Number of milliseconds a producer is willing to wait before sending a batch out. ( default 0)
- By introducing some lag ( for example linger.ms=5 ) we increase the chances of messages being sent together in a batch
- By introducing a small delay, we can increase throughput, compression and efficiency of a producer
- If a batch is full ( batch.size ) before the end of the linger.ms period, it will be sent to kafka right away!
batch:size:
Maximum number of bytes that will be included in a batch. The default is 16KB.
- Increasing a batch size to 32KB or 64KB can help increasing the compression, throughput, and efficiency
- Any message that is bigger than the batch size will not be batched
- A batch is allocated per partition, so make sure that you don't set it to a number that is too high other it will waste memory
- You can monitor the average batch size metric using kafka producer Metrics
Advantages:
- Much smaller producer request size
- Low latency
- Better throughput
- Store messages on disk are smaller in broker
Disadvantages:
- Producers must commit some CPU cycles to compression
- Consumers must commit some CPU cycles to decompression
Note: If the producer produces faster than the broker can take, the border can take the records will buffer in buffer.memory and fill back down when the throughput to the broker increases max.block.ms=60000: the time .send() will block until throwing an exception.
- The producer has fill up its buffer
- The broker is not accepting any new data
- 60 seconds has elapsed
Consumers:
Consumers read data from topics
- Kafka stores the offsets at which a consumer group has been reading
- It will be stored in a Kafka topic and that Kafka topic is named __consumer_offsets.
- When consumer in a group has processed data received from kafka, it should be comitting the offsets
- If a consumer dies it will be able to read back from where it left off.
Delivery Semantics:
- At most once: Offsets are committed as soon as the message batch is received. If the processing goes wrong, the message will be lost.
- At least once (usually): Offsets are committed after the message is processed. If the processing goes wrong, the message will be read again. This can result in duplicate processing of messages. Make sure your processing is idempotent ( unique)
- Exactly once: It can be achieved for Kafka to Kafka workflows using Kafka Streams API. For Kafka to External System workflows use an idempotent consumer.
There are two ways to make consumer record idempotent ( Unique)
- Kafka generic id:- You can take the help of kafka to generate unique id by appending simple strings like String id = record.topic()+"-"+record.partition()+"-"+record.offset();
- Application supplied unique value: You can generate unique value from producer supplied record.
Consumer offset strategy:
- enable.auto.commit = true & synchronous processing of batches, offsets will be committed automatically for you at regular interval by default auto.commit.interval.ms=5000, every time your call .poll(), if you don't use synchronous processing, you will be in "at-most-once" behavior because offsets will be committed before your data is processed
- enable.auto.commit = false & synchronous processing of batches. you control when you commit offsets and what's the condition for committing them.
Consumer offset reset strategy:
- auto.offset.reset=latest // will read from the end of the log
- auto.offset.reset=earliest // will read from the start of the log
- auto.offset.reset=none // will throw exception if no offset is found
if a consumer hasn't read new data in 7 days, consumer offset can be lost, it can be controlled by offset.retention.minutes
To Replay data for a consumer group
Take all consumer from a specific group down
Use kafka-consumer-groups command to set offset to what you want restart consumers
Poll Behavior:
fetch.min.bytes:
- Controls how much data you want to pull at least on each request
- Helps improving throughput and decreasing request number
- At the cost of latency
Max.poll.records ( default 500)
- Controls how many records to receive per poll request
- Increases if you messages are very small and have a lot of available RAM
- Good to monitor how many records are polled per request.
Considerations
- set proper data retention period & offset retention period
- Ensure the auto offset reset behavior is the one you expect / want
- use replay capability in case of unexpected behavior
Zookeeper:
- Manages brokers keeps a list of them
- It helps in performing leader election for partitions.
- It sends the notification to Kafka in case of changes. ( e.g. new topic, broker dies, broker comes up, delete topic etc.)
- Kafka can not run without zookeeper.
- It by design operates with an odd number of servers.
- It has a leader(Leader handle the writes from the brokers) the rest of the servers are followers (handle reads).
- Zookeeper does not store consumer offsets with Kafka.
Kafka Guarantees:
- Messages are appended to a topic-partition in the order they are sent.
- Consumers read messages in the order stored in a topic-partition.
- With a replication factor of N, producers and consumers can tolerate up to N-1 brokers being down.
- As long as the number of partitions remains constant for a topic, the same key will always go to the same partition.